Learn and build better businesses at Business of Software Conferences
BoS USA 2024
23-25 September | Raleigh, NC
“Software people of the world: If you haven’t been to a Business of Software Conference, you should go. If you have already been, I don’t need to convince you. You already know.”
Dharmesh Shah, Co-Founder/CTO, HubSpot
Get the latest updates
Get ahead with conference updates, newly published talks, blogs, and exclusive details. Be the first in the know.
Next Events
23-25 September – 🇺🇸 Raleigh NC
BoS USA returns to Raleigh NC
Watch the latest BoS Talks in the BoS Library
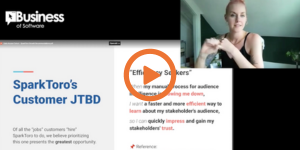
JTBD : SparkToro case study
Technology is Not Neutral
Subscribe to Business of Software
Learn how GREAT software companies are built, run, and scaled.
You can join a welcoming community of SaaS leaders for thoughtful networking and interactive events designed to help you connect with and learn from experts and your peers.
Get exclusive new talks straight into your inbox.
Latest
- On the grounds of Churchill College, the Business of Software Conference Europe once again unfolded last 25-26 March 2024. Sunday – Pre-conference activities Prior to the official start of the BoS Conference Europe […]
- Copy for software company websites should be anything but boring. Joanna Wiebe teaches how to ditch bad words and write copy that converts.
- There is no one-size-fits-all approach to founding a startup. Don’t be afraid to break 'business rules' and ignore advice that doesn't fit.
Learn how great SaaS & software companies are run
We produce exceptional conferences & content that will help you build better products & companies.
Join our friendly list for event updates, ideas & inspiration.